안녕하세요,



저번 포스팅에 이어서 계층 구조 분석에 대해 심층 분석을 해보고자 합니다.
그리고 다소 이해가 어려우셨을 수도 있는 Top-Base의 관계에 대해 추가적인 설명 안내 드립니다.

계층 구조 분석은 쉽게 4 단계로 먼저 정의할 수 있습니다.
1. 원본 트렌드 데이터 분석 (BEM)
2. 배치 수준 데이터 생성 (BLM)
3. 배치 수준 데이터 및 배치 조건 (결과 및 초기값) 데이터를 융합한 기반 모델 생성 (Base, BLM)
4. 배치 조건 데이터 및 기반 모델 융합 모델 생성 (Top, BLM)
얼핏 보면 3번과 4번 과정은 왜 있는지 의문이 들 수도 있습니다.
이번 데모의 목표는 공정 초기에 어떤 공정 파라미터를 조절해야 더 높은 결과치를 얻을 수 있는가 입니다.
따라서 공정 초기 조건과 결과를 1:1로 비교해야 하는데, 이것 만으로는 부족하겠죠.
그래서 3번 과정에서 조건 데이터와 원본 공정 데이터를 가지고 기반 데이터를 생성하게 되는 것입니다. 4번에서는 그렇게 생성된 기반 데이터를 가지고 초기 조건과 결과를 비교하게 되는데, 이 때 기반으로 사용한 데이터에서 Score 값을 제공 받음으로 인해 연관 관계를 파악하는대 도움을 주게 됩니다.
서두가 다소 길어졌네요 ^^;
이번 시간의 핵심은 저번 포스팅 마지막에 있었던 그래프에서 '신빙성'과 '연속성'에 대한 부분을 검토하고자 합니다.
 |
저번 포스팅에서는 이 그래프를 끝으로 어떤 파라미터가 좋다더라~ 고만 마무리를 했습니다.
그럼 과연, 그 데이터는 우리가 얼마나 믿을 수가 있을까요?
SIMCA에서는 더블 클릭을 통해 데이터의 하층 레이어를 살펴볼 수 있는 드릴 다운 기능을 제공합니다.
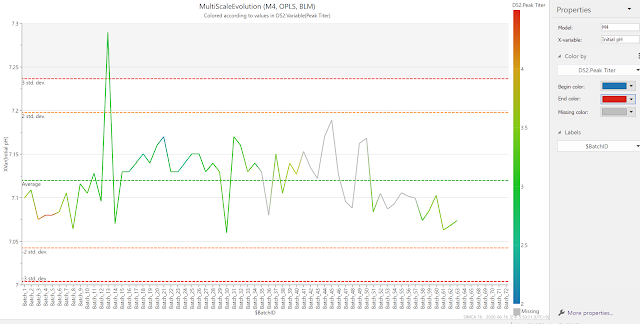
위의 데이터에서 Initial Glucose 파라미터를 한 번 살펴보겠습니다.

각 배치에 대한 Initial Glucose 값을 보여주고 있습니다.
여기에 색을 입혀서 붉은 색에 가까울수록 Peak Titer가 높은 배치임을 알 수 있게 하였습니다.
분명 Coefficient에서는 Initial Glucose는 높을 수록 좋을 것이다. 라는 메시지를 주고 있지만, 대문자 I 모양의 막대기 길이로 보아 결과가 상당히 들쑥 날쑥 하다는 것을 암시하고 있습니다. 결과에서도 일부 배치만 Peak Titer가 높았으며, 나머지는 대부분이 평이한 결과를 기록하는 것으로 나타나있어, Initial Glucose가 무조건 높다고 좋은 결과가 나오지는 않을 수도 있다고 볼 수 있습니다.
그럼 이번엔 Initial pH를 알아볼까요? 상대적으로 I바 크기가 작아 결과를 유추하는대 보다 도움이 될 것이라 생각이 됩니다.

이번에는 낮은 배치에서 Peak Titer가 더 높음을 관찰하여 어느 정도 신빙성이 있었음을 알 수 있었습니다. 이런 방식으로 한단계 더 들어가서 Coefficient에서 제시한 파라미터의 기여도를 신뢰성이 있는지 없는지 판단할 수 있게 됩니다.
마지막으로 결과치의 Coefficient가 시간대별로 어떻게 변했는지 추이도 확인할 수 있습니다. 위에서 3번 과정에서 생성했던 모델의 Loading을 살펴보면 아래와 같이 나옵니다.
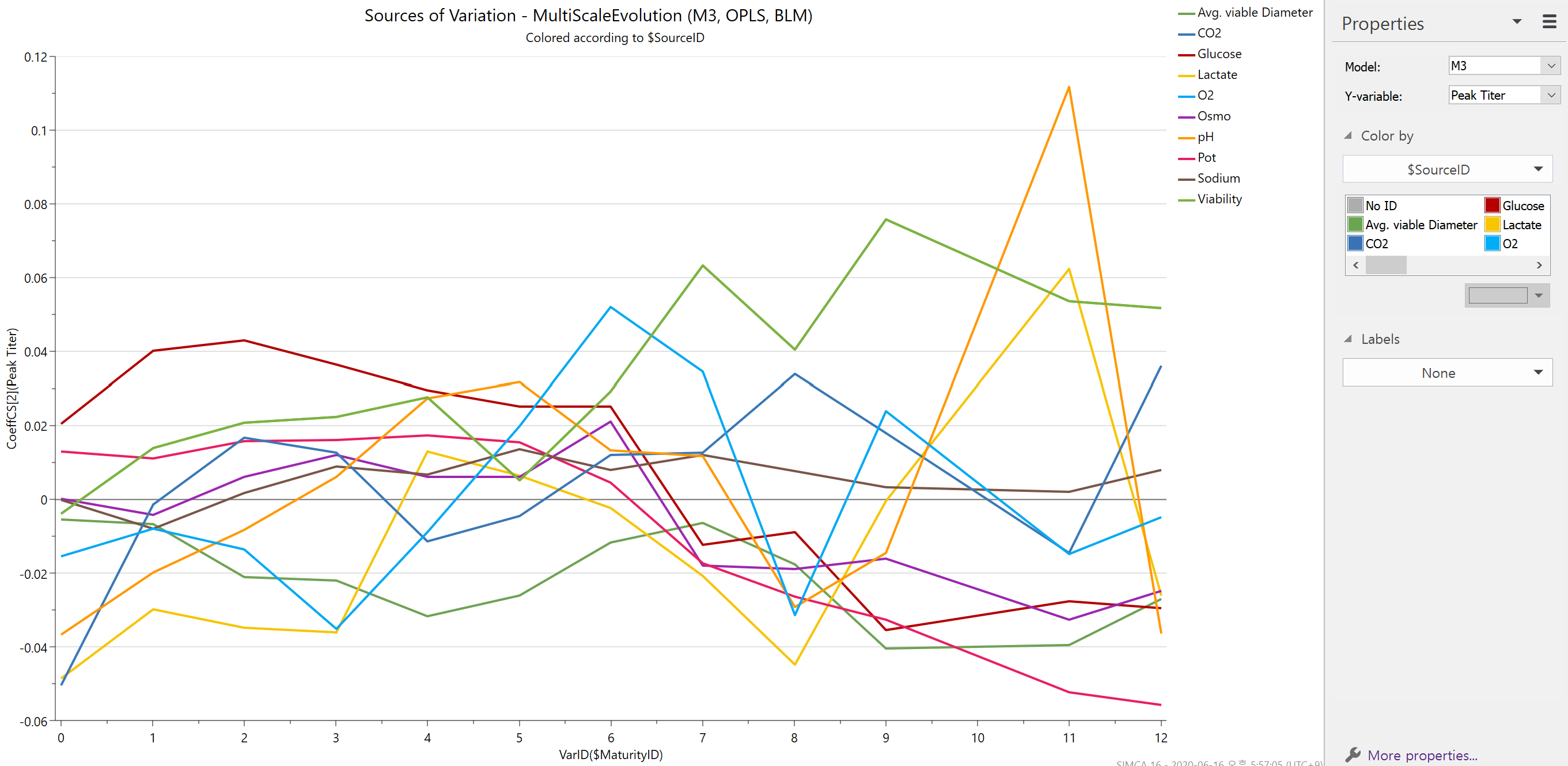
해당 그래프를 통해서 파라미터 별로 특정 결과치 (그래프에서는 Peak Titer) 에 대해 시간이 지날 수록 중요도가 어떻게 달라졌는지 파악하여 공정 초기 뿐만이 아니라 중반, 후반의 전략도 새롭게 가져갈 수 있음을 알 수 있습니다.
다음 시간에도 보다 유익한 정보로 찾아뵐 수 있도록 하겠습니다~
댓글
댓글 쓰기